
Loadtesting
2022-8-16 About 12 min
# Loadtesting
In this chapter we are going to look at how we are going to load test our server and website. We are going to use special software to give our website many visitors to see how our server is going to react.
# Why
If the COVID-19 crisis had taught us one thing in terms of IT, it is that we need to load test! Many in-person events were replaced by online alternatives. As a result, complaints of slow or even inaccessible websites rained down during this period.
In March 2021 an online Batibouw event took place, which was a great success and many people wanted to register on the platform at the beginning of the day. However, the servers could not handle these large numbers, and the event even had to close for several days because of this.
batibouw was down in March 2021](./batibouw.png)
While predicting the number of visitors may not always be possible, in our business we can garatnies whether a certain number of visitors will have consequences. One way we do this is through load testing. We can simulate a large number of simultaneous logins, giving us an idea of how the server will react, detecting bottlenecks and perhaps drawing up plans for scaling up.
We saw the same story happen at Smartschool during the first "cooling off week" (in which online education became mandatory for all students). Smartschool experienced problems with high traffic to the platform. Again, we were able to avoid this by running a test on the server whether we could indeed handle all students logging in at the same time.
# Definition
Load testing is simulating the use of a service by multiple users. Usually for software that can be used by multiple users simultaneously, such as web servers in our case. You can also test other software, such as a word processor by loading it with a very large file, that too is load testing.
The most accurate tests simulate effective usage rather than theoretical usage. However, this usually requires special software or a script created for the hosted application. For example, we can simulate 1 000 000 attempts to log in versus 1 000 000 attempts to request the page that an "off the shelf" tool gives us. The former is going to simulate an entire interaction and give us more security.
Load testing allows you to measure Quality of Service (QoS). This gives us a description and measurement of the quality and performance of a service.We eemmeasure a "system/software under test" (SUT) or "device under test" (DUT). Here we look at a few properties:
- CPU
- Memory
- Disk activity
- Response time
From good load testing we can start to identify problems, those problems can come from:
- The software being tested
- The database server
- Network: latency, congestion
- Client-side problems
- Load balancing
If you have a Service Level Agreement (SLA) in the business world, you have to prove it through load testing. An SLA contract (within companies this is often also between departments) defines certain requirements of services.
This can include:
- Service availability: the amount of time the service is available for use. This can be measured in percentages of time, with 99.5 percent availability, for example. That gives us 7m 12s per day that our server is unavailable, you can calculate this with the uptime Calculator (opens new window). In modern IT applications we speak in "nines" because we usually go for 99.9% or 99.99% etc.
- Defect rates: percentages of errors that are possible. Production errors such as incomplete backups and restores, coding errors/rework, and missed deadlines can be included in this category. Also, for example, a percentage of dataloss so a backup service can give 99.9999% assurance of not losing your data.
- Maintenance notification: an SLA can also state how far in advance a possible maintenance has to be notified and within which hours this may be performed.
- Support: very often an SLA also states how quickly a support ticket must be handled (not solved), for example, you may have a contract with your Internet provider that says a technician must be on site within 5 hours.
- Security: verifiable security measures are often also contained in an SLA: such as antivirus updates and patching times. This is often essential to demonstrate that all reasonable preventive measures have been taken, should a security incident occur.
- Performance: perfomance under a certain pressure is also often in an SLA. This allows us to stipulate, for example, that a number of users can load their website within a certain load time.
# Stress testing?
When you test how much your users can handle your SUT or software, it's also called stress testing The line between load testing and stress testing is blurred. When you notice during load testing that the service becomes slow and non-responsive, it is no longer a load test but a stress test.
You can briefly say that a stress test goes to greater extremes to start discovering the limits of a system.
# Terminology
Network latency: how quickly the server responds to a request.
- Often called response time.
- Measured in ms. Lower numbers mean the response time is faster
- Measured from the client, so network overhead includes time
- This can also be a bottleneck to consider
Throughput: how many requests the server can handle in a specific time frame
- Usually reported in requests per second
# Scaling
So how do we scale a system? We have two options:
Vertical scaling: this is the simplest method of scaling servers. We add to 1 server more resources, more CPU, more RAM,.... This works smoothly and easily up to a certain level where there is no more better hardware to get. Also, in many cases this comes out expensive, especially if we have to buy specialized hardware.
Hori number scaling: in theory it seems simple, we buy more servers to subdivide the traffic. However, this is not so easy for any system, we need to be able to make a distribution on the traffic itself without inconveniencing users. The software must also be designed to share traffic across servers. We do have much larger room for expansion, the biggest limiting factors here are budget and software.
Diagram scaling](./scale.png)
In practice, combinations often occur. For example, a web application itself is more likely to be scaled horizontally and the underlying database vertically because splitting up a relational database is much more difficult.
# Web server load testing
We have set up a dynamic website on our own server in the last few lessons. We are now going to load test it.
In this chapter, we are going to simulate HTTP traffic to our web server to answer some questions
- Does the server have enough resources (CPU, RAM, ...) to handle the requests?
- Is the server responding fast enough?
- Is the application responding fast enough?
- Do we possibly need to scale vertically or horizontally to meet the requirements?
- Are there specific pages or applications that run slowly?
# The test plan
note
This step in practice easier if we have comprehensive monitoring like prometheus, collectd, icinga, etc.... We will see this in the follow-up box DevOps (opens new window)!
# Step 1: view resources
We need to make sure that we can view server resources. This way we can already have a view of the capacity our server has.
Memory:
free -m
1
With free we can view the current memory usage. -m indicates to do this in Megabyte, alternatives are -g for gigabyte (rounded) or -h for auto rounding.
$ free -m
total used free shared buff/cache available
Mem: 31819 4486 19613 1025 7719 25857
Swap: 2047 0 2047
1
2
3
4
2
3
4
Here we see the usage of RAM memory as well as Swap in use. We have a number of columns:
total: the total memory the server hasused: the total memory in usefree: the total memory that is `emptyshared: how much memory is used bytmpfsas "RAM disk" for processes in Linuxbuff/cache: how much memory is used by caching the hard driveavailable: how much memory available for use (free+buff/cache, because the cache is not essential, only for extra speed)
CPU:
mpstat
1
With mpstat we can view the same thing as free but for the CPU.
Linux 5.13.0-30-generic 03/03/2022 _x86_64_ (8 CPU)
11:55:35 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:55:35 AM all 5.67 0.02 1.92 0.18 0.00 0.14 0.00 0.00 0.00 92.06
1
2
3
4
2
3
4
Here we see it expressed as a percentage.
usr: percentage of CPU time used by user processesnice: the CPU usage by the user innicemode, these are background processes that may go very slowsys: percentage of CPU time used by the Linux kerneliowait: percentage of CPU time where we are waiting on the hard diskirq: percentage of CPU time used by hardware interruptssoft: percentage of CPU time used by software interruptssteal: percentage of time the system waits for a CPU, we see this in VMs, if this is high it means that other VMs are "stealing" our CPU timeguest: percentage of CPU time used by VMs in our servergnice: percentage of CPU time used byniceprocesses of VMsidle: percentage of CPU time not in use
Both (live):
The top commands only give us a snapshot. We can use watch to update them automatically but we have better tools to do this.
The first one is the best known:
top
1
top shows a combination of the above commands. As well as a process list.
We can go a step further with the newer htop:
htop
1
htop is an improved top that also provides graphical display. As well as an indication in colors and many extension possibilities!
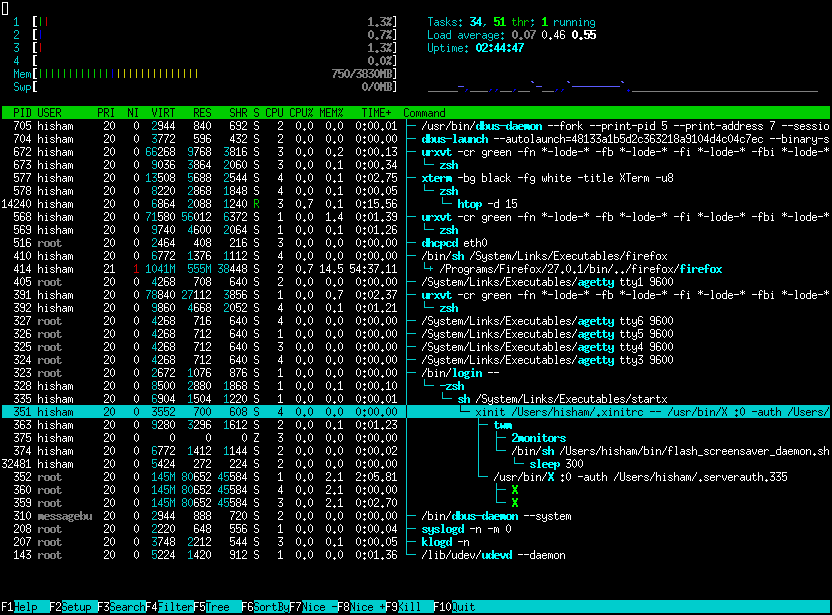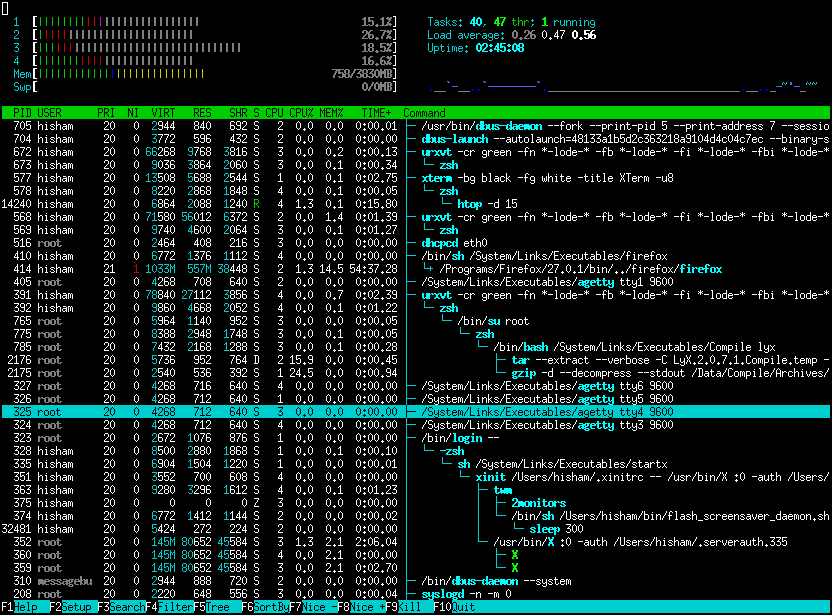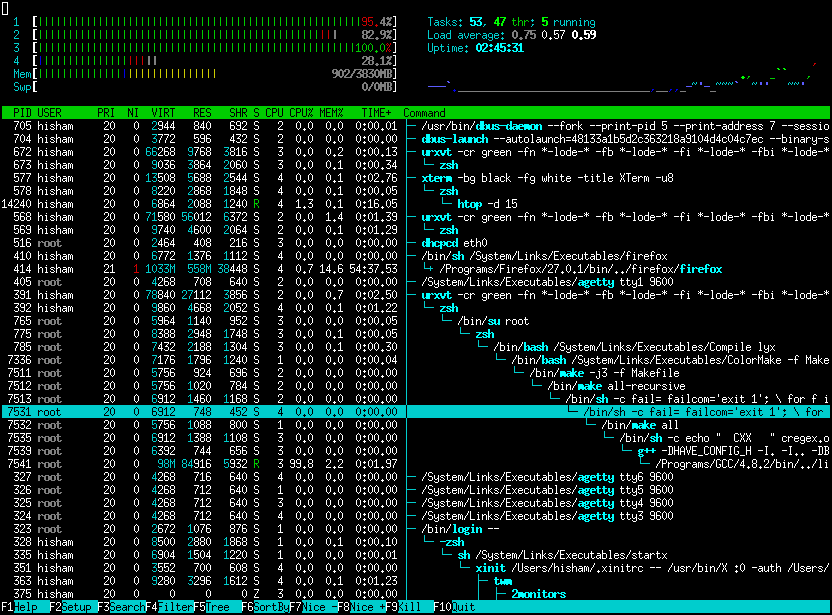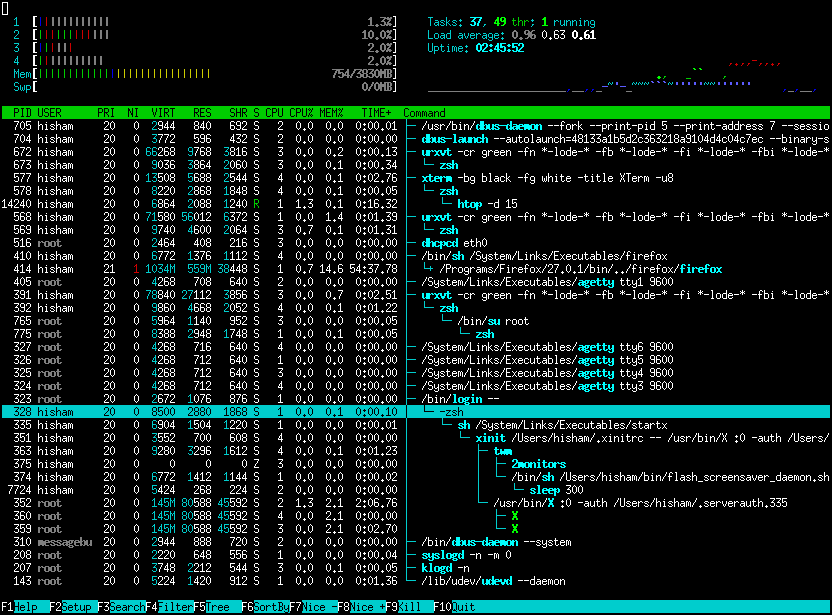
htop is loved in the community and runs on many systems as you can see on their site (opens new window)
TIP
We are going to want to run these commands during testing, it is best to use 2 terminal windows side by side! 1 with htop and 1 for our testing.
# Step 2: find maximum throughput
note
Normally you would perform these steps on two different computers. We do it on the same server, which is going to make the results less reliable because our server is experiencing load from its own test software.... But it does work very well to explain the concepts and basics.
We are going to look for the limits of our server. We are going to send as many requests as possible. With this we will measure the limits of our throughput.
We are going to find that our server is going to have a lot of capacity but at the expense of speed. So while in theory we can handle this it is not so in practice. However, our users are going to be bothered if your web page takes 20 seconds to load!
Skilled research shows that 79% of online store customers cancel their purchases or do not return for more purchases in the future if they find the website "slow" [1]. 64% think a web page should load within 4 seconds on a smartphone, 47% even say it should be 2 seconds on a desktop.
So we're going to scale back our maximum to an acceptable load time to determine our practical maximum throughput.
# wrk2
wrk2 is an HTTP benchmarking tool based on wrk.
wrk2 is wrk modified and improved to produce constant throughput loads, and accurate latency details down to the high 9's. wrk2 (like wrk) is a modern HTTP benchmarking tool capable of generating significant load when run on a single multi-core CPU, it uses multiple CPU threads to efficiently send requests.
An optional Lua script can generate HTTP requests, process responses, and run custom reporting. We will not use this in the course but in practice you can simulate full user interactions!
# Installation
wrk2 is not found in APT, but it is written in C so going to compile it yourself is a good option. We are also going to use the fork from Kinvolk (opens new window), it contains some useful bug fixes like ARM compatibility.
sudo apt update
sudo apt install build-essential libssl-dev git zlib1g-dev
1
2
2
This installs the software needed to compile C code as well as a few libraries that wrk2 uses.
mkdir ~/src && cd ~/src
git clone https://github.com/kinvolk/wrk2.git
cd wrk2
1
2
3
2
3
We create a folder and copy the code from the GitHub repository to this folder.
make
1
Next, we compile the code.
sudo cp wrk /usr/local/bin
cd ~
rm -rf ~/src/wrk2
1
2
3
2
3
Finally, we move the binary and clean up the code again.
# Usage
We are going to use wrk2 to find our maximum throughput
wrk -t10 -c10 -d30s -R10000 http://localhost
1
The options:
-t: how many CPU thread are used by the program wrk-c: how many connections must remain open-d: duration of the test-R: throughput in requests/sec (total). We set this very high to find our maximum
When we go to run this we get something like:
$ wrk -t10 -c10 -d30s -R10000 http://localhost
Initialized 10 threads in 1 ms.
Running 30s test @ http://localhost
10 threads and 10 connections
Thread calibration: mean lat.: 1.306ms, rate sampling interval: 10ms
[...]
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.27ms 0.93ms 27.82ms 94.38%
Req/Sec 1.05k 110.19 2.78k 81.10%
299993 requests in 30.00s, 119.00MB read
Requests/sec: 9999.50
Transfer/sec: 3.97MB
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
With a maximum of 9999 requests/sec out of the 10 000 we requested, we see that our server has no problems! Our largest response time was 27ms which is good.
We did test this over the loopback interface, maybe not realistic.... We use our external interface for the following test:
$ wrk -t10 -c10 -d30s -R10000 http://rnummer.stuvm.be
Initialized 10 threads in 1 ms.
Running 30s test @ http://lier.stuvm.be
10 threads and 10 connections
Thread calibration: mean lat.: 3311.794ms, rate sampling interval: 11771ms
Thread calibration: mean lat.: 3393.139ms, rate sampling interval: 11886ms
Thread calibration: mean lat.: 3385.360ms, rate sampling interval: 11845ms
Thread calibration: mean lat.: 3349.928ms, rate sampling interval: 11763ms
Thread calibration: mean lat.: 3345.097ms, rate sampling interval: 11755ms
Thread calibration: mean lat.: 3362.592ms, rate sampling interval: 11821ms
Thread calibration: mean lat.: 3363.478ms, rate sampling interval: 11788ms
Thread calibration: mean lat.: 3364.863ms, rate sampling interval: 11829ms
Thread calibration: mean lat.: 3340.271ms, rate sampling interval: 11812ms
Thread calibration: mean lat.: 3361.703ms, rate sampling interval: 11902ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 13.07s 3.74s 19.66s 57.94%
Req/Sec 350.50 1.50 352.00 90.00%
103839 requests in 30.00s, 38.62MB read
Requests/sec: 3461.15
Transfer/sec: 1.29MB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
3461.15 requests/sec is already a bit less than the 10 000 requests/sec we requestedm we also see a maximum load time of 19 seconds! We have already exceeded our throughput here!
StuVM Network
Why this big difference? for that we need to take a look at how StuVM is built.
StuVM network](./net.png)
Because we have 1 IP to the outside we use a dedicated proxy server (opens new window) that is going to forward traffic based on the domain name to the appropriate server at the TCP level.
In a normal class setting we are going to run ~30 load tests at a time against our connection, and our proxy server. This is going to be our bottleneck in this scenario. We're going to bypass this by overwriting the IP address of your domain locally to our localhost.
sudo nano /etc/hosts
1
We'll add the following line at the bottom:
127.0.0.1 r<number>.stuvm.be wordpress.r<number>.stuvm.be php.r<number>.stuvm.be
1
Loading a static page is something NGINX can do very quickly; it is also designed to handle thousands of requests. We set up WordPress in previous chapter, this is already going to be a nicer test.
wrk -t10 -c10 -d30s -R10000 http://wordpress.r<number>.stuvm.be
1
We see a very clear difference! Getting 48 requests/sec and a maximum load time of 29 seconds!
$ wrk -t10 -c10 -d30s -R10000 http://wordpress.r<number>.stuvm.be
Initialized 10 threads in 1 ms.
Running 30s test @ http://wordpress.lier.stuvm.be
10 threads and 10 connections
Thread calibration: mean lat.: 5771.160ms, rate sampling interval: 18071ms
[...]
Thread Stats Avg Stdev Max +/- Stdev
Latency 19.94s 5.73s 29.84s 57.89%
Req/Sec 5.00 0.00 5.00 100.00%
1452 requests in 30.01s, 76.27MB read
Requests/sec: 48.38
Transfer/sec: 2.54MB
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
We now take the 48 requests/sec we got and use it as throughput.
wrk -t10 -c10 -d30s -R48 http://wordpress.r<number>.stuvm.be
1
We see that our load times have now become reasonable:
$ wrk -t10 -c10 -d30s -R48 http://wordpress.r<number>.stuvm.be
Initialized 10 threads in 1 ms.
Running 30s test @ http://wordpress.lier.stuvm.be
10 threads and 10 connections
Thread calibration: mean lat.: 119.670ms, rate sampling interval: 334ms
[...]
Thread Stats Avg Stdev Max +/- Stdev
Latency 169.06ms 58.07ms 336.64ms 60.64%
Req/Sec 4.28 1.20 8.00 89.98%
1438 requests in 30.01s, 75.53MB read
Requests/sec: 47.92
Transfer/sec: 2.52MB
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
If the values here are in an acceptable range, increase the R value again until we have just an acceptable value. When you reach that, you have the real maximum throughput!
# mysqlslap
We have seen a load test for our HTTP server. We were able to isolate NGINX here before but also did a full test by load testing WordPress. This also put pressure on MariaDB. We also have a separate test for MariaDB itself to be able to load test.
mysqlslap is a tool we use to perform a load test on our database. We briefly run the command:
sudo mysqlslap
1
Now we get an error...
$ sudo mysqlslap
mysqlslap: unknown variable 'default-character-set=utf8mb4'
1
2
2
In recent versions of MariaDB a variable has been removed which Ubuntu still provides in the default installation.
We are going to comment it out so we can execute mysqlslap.
sudo nano /etc/mysql/mariadb.conf.d/50-client.cnf
1
We adjust the configuration so that we have the following:
#default-character-set = utf8mb4
1
Now we can run a load test:
sudo mysqlslap --auto-generate-sql --verbose
1
With --auto-generate-sql we are going to ask to automatically create a database and test on it, and --verbose makes sure we get more output.
$ sudo mysqlslap --auto-generate-sql --verbose
Benchmark
Average number of seconds to run all queries: 0.115 seconds
Minimum number of seconds to run all queries: 0.115 seconds
Maximum number of seconds to run all queries: 0.115 seconds
Number of clients running queries: 1
Average number of queries per client: 0
1
2
3
4
5
6
7
2
3
4
5
6
7
We don't see much load yet because mysqlslap only ran 1 concurrent test. With the following command we request 50 concurrent connections, which the query executes 10 times
sudo mysqlslap --concurrency=50 --iterations=10 --auto-generate-sql --verbose
1
We are already getting to see some more load:
$ sudo mysqlslap --concurrency=50 --iterations=10 --auto-generate-sql --verbose
Benchmark
Average number of seconds to run all queries: 0.293 seconds
Minimum number of seconds to run all queries: 0.236 seconds
Maximum number of seconds to run all queries: 0.429 seconds
Number of clients running queries: 50
Average number of queries per client: 0
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
The table being created is very simple, we can make this one a little more elaborate: we add 5 numeric columns and 20 character columns:
sudo mysqlslap --number-int-cols=5 --number-char-cols=20 --concurrency=50 --iterations=10 --auto-generate-sql --verbose
1
$ sudo mysqlslap --number-int-cols=5 --number-char-cols=20 --concurrency=50 --iterations=10 --auto-generate-sql --verbose
Benchmark
Average number of seconds to run all queries: 0.854 seconds
Minimum number of seconds to run all queries: 0.746 seconds
Maximum number of seconds to run all queries: 1.037 seconds
Number of clients running queries: 50
Average number of queries per client: 0
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
With mysqlslap we can also perform a load test on our database, which again gives us a better idea of the capabilities of our server.
# The Next Generation: Horizontal Autoscaling
We have seen several ways to scale up. Now with more and more servers in the cloud, you can usually start scaling in a few clicks. But we can also do this automatically!
Let's take a look in the Kubernetes world: Horizontal Pod Autoscaling (opens new window) is a mechanism that will constantly monitor load on servers (containers to be exact), after this the system will draw conclusions about the load and possibly create more containers to distribute load. One step further is to be able to use an API from your cloud provider to rent additional servers to expand. This way, peaks in traffic can be handled perfectly automatically. In practice, however, this is not yet widely used.
The reverse is also useful, most websites see traffic in a sine wave form, linked to the time of day. For example, outlook will peak during business hours and Netflix will peak around 8 in the evening. Then again, in the middle of the night, you might need fewer servers. Autoscaling is also going to be able to manage this to be more efficient with servers.